

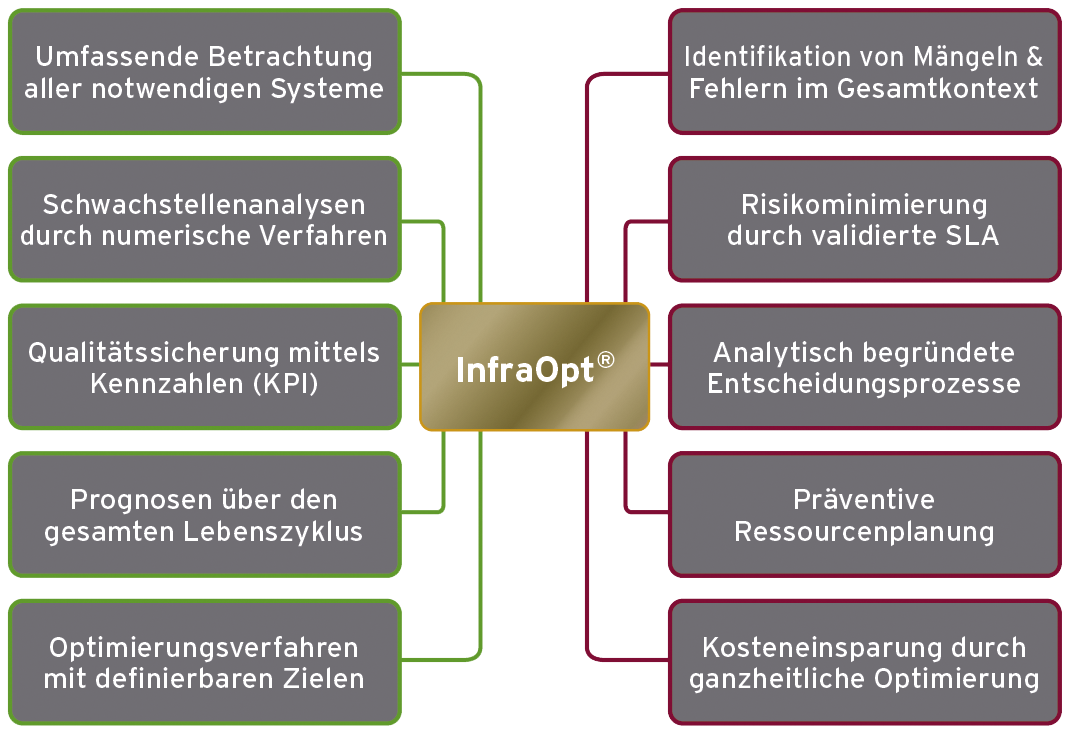
Resilienz als Management-Grundlage
... im Design
... in der Planung
... im Betrieb
Beste Resultate versprechen Rechenzentren, die bereits während des Designs der Resilienz-Analyse unterzogen werden.
Optimierungsschritte können so in die Planung einfließen.
Kontinuierliche Überwachung sichert den unterbrechungsfreien Betrieb über den gesamten Lebenszyklus.
Unser bewährter Prozess:
Gibt es das „optimale Rechenzentrum“?
InfraOpt® beantwortet diese Frage mit Ja!
Allerdings ist das optimale Rechenzentrum stets abhängig von den spezifischen Anforderungen unter Berücksichtigung der gegebenen Möglichkeiten.
Eine zentrale Bedeutung spielt dabei die europäische Normenreihe EN 50600 bzw. ihre internationalen Gegenstücke ISO/IEC 22237 und ISO/IEC 30134.

Unser Beitrag zur Normierung
In der Rechenzentrums-Praxis ist es hilfreich, über einheitliche Definitionen von SLA zu verfügen. Deren Einhaltung kann mittels aussagekräftiger Key Performance Indicator (KPI) gemessen werden, welche die verschiedenen Aspekte der Resilienz beziffern.

Resilienz als Grundlage von Service-Level-Agreements
Welche Aspekte sollte ein SLA umfassen?
Verfügbarkeitsklasse gemäß EN 50600-1 bzw. ISO/IEC 22237-1
Berichtszeitraum in Jahren
Maximal zulässige Anzahl von Service-Verletzungen im Berichtszeitraum
Maximal zulässige Zeitspanne der Nichtverfügbarkeit im Berichtszeitraum
Maximale Anzahl von 1-Fehler-Punkten (SPoF) der Infrastruktur
Verfügbarkeit, berechnet am Infrastruktur-Modell

Ganzheitliche Planung mithilfe Resilienz-Optimierung
Analysten transformieren das Resilienz-Diagramm in die Simulations-Software InfraOpt64. Die Teilsysteme erhalten Daten und Eigenschaften, so dass ein Modell der zu untersuchenden Infrastruktur entsteht.
An diesem Infrastruktur-Modell können SLA validiert als auch zielgerichtete Optimierungen von Resilienz-Aspekten durchgeführt werden, durch:
Berechnung der Zuverlässigkeit
Berechnung der Inhärenten und Operationalen Verfügbarkeit
Berechnung der 1- und 2-Fehlertoleranz
Berechnung der reduzierten Verfügbarkeit im 1- und 2-Fehlerfall
Blackout Simulation
Design-Variationen mit verschiedenen Redundanzen
Analysen mit verminderter Last
Vergleich verschiedener Teilsysteme
Importanz-Analysen
... u. v. m.

1) Vergleichende Resilienz-Analyse von Rechenzentrums-Infrastrukturen
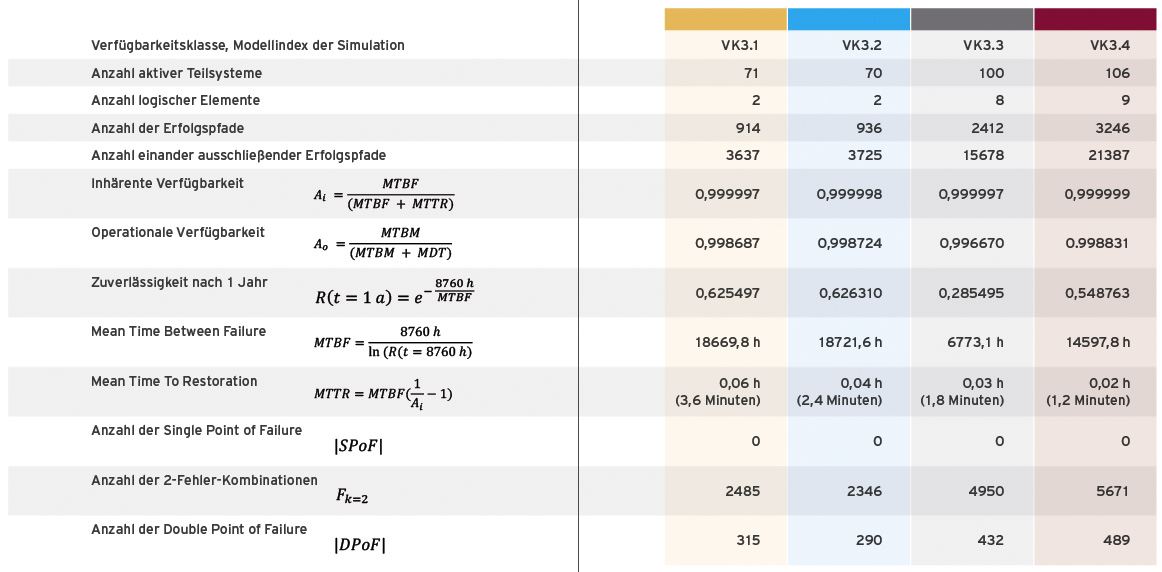
2) Grafischer Vergleich der Analyseergebnisse

Was bedeutet Inhärente Verfügbarkeit?
Inhärente Verfügbarkeit ist KPI für die Wahrscheinlichkeit, dass die Infrastruktur unter idealen Betriebs- und Wartungsbedingungen erwartungsgemäß funktioniert.
Es werden keine Zeiten für die Initiation der Instandsetzung, Ersatzteilbeschaffung oder Logistik berücksichtigt.
Als Aspekt der Resilienz hat die Inhärente Verfügbarkeit folgende praktische Bedeutung:
Anwendung in den Phasen Design bzw. Planung
Vergleich von Varianten
Bestimmung von Redundanzen
Abhängig von den Metriken MTBF und MTTR
Was bedeutet: Mean Time Between Failure (MTBF)?
MTBF beziffert die durchschnittliche Zeitspanne zwischen aufeinanderfolgenden Ausfällen.
Was bedeutet: Mean Time To Restoration (MTTR)?
MTTR beziffert die durchschnittliche Zeitspanne zur Reparatur oder zum Austausch, ohne Verzögerungen durch Logistik, wie Mobilisierung, Beschaffung etc.

Was bedeutet Operationale Verfügbarkeit?
Operationale Verfügbarkeit ist KPI für die Wahrscheinlichkeit, dass die Infrastruktur unter den gegebenen Betriebs- und Wartungsbedingungen erwartungsgemäß funktioniert.
Dabei werden geplante und ungeplante Ereignisse sowie erforderliche Zeiten für Logistik berücksichtigt.
Als Aspekt der Resilienz hat die Operationale Verfügbarkeit folgende praktische Bedeutung:
Sensibel für die Infrastruktur-Optimierung
Grundlage für Wartungs- und Instandsetzungspläne
Nutzbar zur Logistik-Planung und Materialbevorratung
Abhängig von den Metriken MTBM und MDT
Was bedeutet: Mean Time Between Maintenance (MTBM)?
MTBM beziffert die durchschnittliche Zeitspanne zwischen allen Instandhaltungsereignissen, gleichgültig ob geplant oder ungeplant, einschließlich der Zeit für erforderliche Logistik.
Was bedeutet: Mean Down Time (MDT)?
MDT beziffert die durchschnittliche Ausfallzeitspanne, einschließlich der Zeit für erforderliche Logistik.
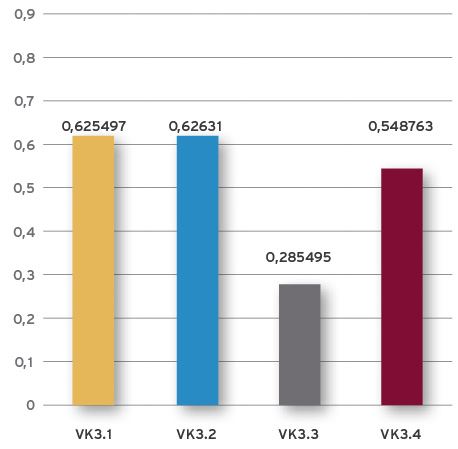
Was bedeutet Zuverlässigkeit?
Zuverlässigkeit ist KPI für die Wahrscheinlichkeit, dass die Infrastruktur fehlerfrei funktioniert, innerhalb einer vorgegebenen Zeitspanne, unter zulässigen Betriebsbedingungen.
Als Aspekt der Resilienz hat die Zuverlässigkeit folgende praktische Bedeutung:
Sensibel für die Infrastruktur-Optimierung
Bestimmung von Redundanzen
Prädiktive Instandsetzung bzw. Austausch
Abhängig von der MTBF und der Betriebszeit
Was ist ein reparierbares System?
Abhängig von inhärenten Redundanzen, muss der Ausfall eines Teilsystems nicht zwangsläufig zum Gesamtausfall des Systems führen. In einem reparierbaren System, wie der RZ-Infrastruktur, kann das fehlerhafte Teilsystem durch Instandsetzung oder Austausch in den Nominalzustand versetzt werden.


Was bedeutet Fehlertoleranz?
Fehlertoleranz einer Infrastruktur bezeichnet die Fähigkeit, im Fehlerfall eines oder mehrerer Teilsysteme weiterhin bestimmungsgemäß zu funktionieren.
Single Point of Failure (SPoF) bezeichnet ein Teilsystem, dessen Ausfall dazu führt, dass die Funktion der Infrastruktur nicht mehr gegeben ist.
Double Point of Failure (DPoF) bezeichnet zwei Teilsysteme, deren gleichzeitiger Ausfall dazu führt, dass die Funktion der Infrastruktur nicht mehr gegeben ist.
Dabei spielt es zunächst keine Rolle, ob die Ursache von Fehlern Ausfälle oder Wartungsmaßnahmen sind.
Die Fähigkeit Fehler zu absorbieren bzw. nach Fehlern zügig in den Nominalzustand zurück zu kehren, sind Aspekte der Resilienz.
Die KPI der Fehlertoleranz, gemessen als Anzahl der SPoF und DPoF, sind Gegenstand von Optimierungen.